底層原理簡(jiǎn)介
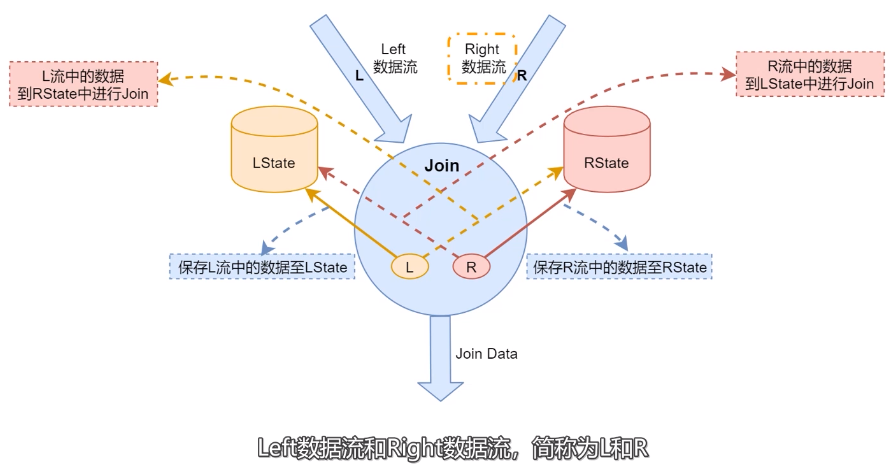
- LState:存儲左邊數據流中的數據�。
- RState:存儲右邊數據流中的數據�����。
- 當左邊數據流數據到達的時(shí)候會(huì )保存到LState�,并且到RState中進(jìn)行Join�。將Join生成的結果數據發(fā)送到下游�。
- 右邊數據流中數據到達的時(shí)候�,會(huì )保存到RState當中��,并且到LState中進(jìn)行Join�,然后將Join之嚄胡的結果數據發(fā)送到下游���。
為了保障左右兩邊流中需要Join的數據出現在相同節點(diǎn)���,Flink SQL會(huì )利用Join中的on的關(guān)聯(lián)條件進(jìn)行分區�����,把相同關(guān)聯(lián)條件
的數據分發(fā)到同一個(gè)分區里面��。
普通雙流Join
現有訂單表A和支付表B進(jìn)行關(guān)聯(lián)得到匯總表C���。訂單表和支付表初始數據如下:
表A:訂單表數據
| order_id |
timestamp |
| 1001 |
2023-02-04 10:00:00 |
| 1002 |
2023-01-04 10:01:02 |
表B:支付表數據
| order_id |
pay_money |
| order_id |
pay_money |
| 1001 |
80 |
| 1002 |
100 |
inner join
當A表中每一條數據到達時(shí)�����,都會(huì )和B表中的數據進(jìn)行關(guān)聯(lián):
- 當能夠關(guān)聯(lián)到數據時(shí)��,將結果輸出到結果表里面�;
- 當不能關(guān)聯(lián)到數據時(shí)�,不會(huì )將結果輸出到結果表里面�;
所以上述A表和B表的Join結果為:
| order_id |
timestamp |
pay_money |
| 1002 |
2023-01-04 10:01:02 |
100 |
當表B中1001新數據到達時(shí)���,新數據如下所示:
| order_id |
pay_money |
| order_id |
pay_money |
| 1001 |
80 |
此時(shí)結果表的數據為:
| order_id |
timestamp |
pay_money |
| 1002 |
2023-01-04 10:01:02 |
100 |
| 1001 |
2023-02-04 10:00:00 |
80 |
注意
Inner Join 不會(huì )產(chǎn)生回撤流����。
left join
當A表數據到達時(shí)會(huì )主動(dòng)和B表中數據進(jìn)行關(guān)聯(lián)查詢(xún)�,沒(méi)有關(guān)聯(lián)到數據���。也會(huì )輸出結果�����,缺失的字段使用null進(jìn)行補全�。
B表中的數據1002到達之后且A表中的數據1001和1002已經(jīng)到達�����,關(guān)聯(lián)之后表C的數據如下:
| order_id |
timestamp |
pay_money |
| 1001 |
2023-02-04 10:00:00 |
null |
| 1002 |
2023-01-04 10:01:02 |
100 |
當B表中數據1001到達之后�����,也會(huì )主動(dòng)和表A中的數據進(jìn)行關(guān)聯(lián)����,如果表中的數據已經(jīng)輸出過(guò)結果了且缺失字段為null��,此時(shí)
會(huì )產(chǎn)生一個(gè)回撤流��,將之前輸出的數據會(huì )撤掉-D����,在重新輸出完整的數據+I�����。
| order_id |
timestamp |
pay_money |
/ |
| 1001 |
2023-02-04 10:00:00 |
null |
+I |
| 1002 |
2023-01-04 10:01:02 |
100 |
+I |
| 1001 |
2023-02-04 10:00:00 |
null |
-D |
| 1001 |
2023-02-04 10:00:00 |
80 |
+I |
注意
left Join會(huì )產(chǎn)生回撤流���。
Right Join
當表B中1001到達時(shí)����,A表中的數據沒(méi)有到達���,則還是會(huì )輸出數據����,缺失字段使用null代替���。當表B中數據1002到達時(shí)���,A表中的
數據1002已經(jīng)到達此時(shí)可以關(guān)聯(lián)到數據����,關(guān)聯(lián)結果如下:
| order_id |
timestamp |
pay_money |
| 1001 |
null |
null |
| 1002 |
2023-01-04 10:01:02 |
100 |
當表A中數據1001到達時(shí)��,會(huì )主動(dòng)到B表中進(jìn)行關(guān)聯(lián)���,此時(shí)結果中已經(jīng)輸出過(guò)關(guān)于1001的數據���,此時(shí)會(huì )產(chǎn)生一個(gè)回撤流����。
| order_id |
timestamp |
pay_money |
/ |
| 1001 |
null |
null |
+I |
| 1002 |
2023-01-04 10:01:02 |
100 |
+I |
| 1001 |
null |
null |
-D |
| 1001 |
2023-02-04 10:00:00 |
80 |
+I |
注意
Right Join會(huì )產(chǎn)生回撤流�����。
Full Join
當表B中數據1001先到達時(shí)�,會(huì )主動(dòng)到A表中進(jìn)行關(guān)聯(lián)查詢(xún)����,關(guān)聯(lián)不到數據����,還是會(huì )輸出結果��。
當表A中數據到達時(shí)��,會(huì )主動(dòng)和B表中的數據進(jìn)行關(guān)聯(lián)查詢(xún)�����,此時(shí)B表中只有1001的數據����,灌籃不到數據�,還是會(huì )輸出結果�����。
所以此時(shí)關(guān)聯(lián)結果如下:
| order_id |
timestamp |
pay_money |
| 1001 |
null |
null |
| 1002 |
2023-01-04 10:01:02 |
null |
當表A中的1001到達時(shí)�����,會(huì )和B表進(jìn)行關(guān)聯(lián)查詢(xún)����,當表B的1002到達時(shí)���,會(huì )和表A進(jìn)行關(guān)聯(lián)查詢(xún)����,此時(shí)結果如下:
| order_id |
timestamp |
pay_money |
/ |
| 1001 |
null |
null |
+I |
| 1002 |
2023-01-04 10:01:02 |
null |
+I |
| 1001 |
null |
null |
-D |
| 1001 |
2023-02-04 10:00:00 |
80 |
+I |
| 1002 |
2023-01-04 10:01:02 |
null |
-D |
| 1002 |
2023-01-04 10:01:02 |
100 |
+I |
注意
Full Join 會(huì )產(chǎn)生回撤流��。
Interval Join
Interval JOIN 相對于UnBounded的雙流JOIN來(lái)說(shuō)是Bounded JOIN��。就是每條流的每一條數據會(huì )與另一條流上的不同時(shí)間區域
的數據進(jìn)行JOIN���。
語(yǔ)法
SELECT ... FROM t1 JOIN t2 ON t1.key = t2.key AND TIMEBOUND_EXPRESSION
TIMEBOUND_EXPRESSION 有兩種寫(xiě)法�����,如下:
- L.time between LowerBound(R.time) and UpperBound(R.time)
- R.time between LowerBound(L.time) and UpperBound(L.time)
- 帶有時(shí)間屬性(L.time/R.time)的比較表達式����。
Interval JOIN 的語(yǔ)義就是每條數據對應一個(gè)時(shí)間區間的數據區間���,比如有一個(gè)訂單表Orders(orderId, productName,
orderTime)和付款表Payment(orderId, payType, payTime)�。假設我們要統計在下單一小時(shí)內付款的訂單信息���。SQL查詢(xún)如下:
SELECT
o.orderId,
o.productName,
p.payType,
o.orderTime,
cast(payTime as timestamp) as payTime
FROM
Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId AND
p.payTime BETWEEN orderTime AND
orderTime + INTERVAL '1' HOUR
Orders訂單數據
| orderId |
productName |
orderTime |
| 001 |
iphone |
2018-12-26 04:53:22.0 |
| 002 |
mac |
2018-12-26 04:53:23.0 |
| 003 |
book |
2018-12-26 04:53:24.0 |
| 004 |
cup |
2018-12-26 04:53:38.0 |
Payment付款數據
| orderId |
payType |
payTime |
| 001 |
alipay |
2018-12-26 05:51:41.0 |
| 002 |
card |
2018-12-26 05:53:22.0 |
| 003 |
card |
2018-12-26 05:53:30.0 |
| 004 |
alipay |
2018-12-26 05:53:31.0 |
符合語(yǔ)義的預期結果是 訂單id為003的信息不出現在結果表中�,因為下單時(shí)間 2018-12-26 04:53:24.0, 付款時(shí)間是
2018-12-26 05:53:30.0超過(guò)了1小時(shí)付款����。
那么預期的結果信息如下:
| orderId |
productName |
payType |
orderTime |
payTime |
| 001 |
iphone |
alipay |
2018-12-26 04:53:22.0 |
2018-12-26 05:51:41.0 |
| 002 |
mac |
card |
2018-12-26 04:53:23.0 |
2018-12-26 05:53:22.0 |
| 004 |
cup |
alipay |
2018-12-26 04:53:38.0 |
2018-12-26 05:53:31.0 |
這樣Id為003的訂單是無(wú)效訂單�����,可以更新庫存繼續售賣(mài)���。
接下來(lái)我們以圖示的方式直觀(guān)說(shuō)明Interval JOIN的語(yǔ)義�����,我們對上面的示例需求稍微變化一下: 訂單可以預付款(不管是
否合理��,我們只是為了說(shuō)明語(yǔ)義)也就是訂單 前后 1小時(shí)的付款都是有效的��。SQL語(yǔ)句如下:
SELECT
...
FROM
Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId AND
p.payTime BETWEEN orderTime - INTERVAL '1' HOUR AND
orderTime + INTERVAL '1' HOUR
總結
- Flink的流關(guān)聯(lián)當前只能支持兩條流的關(guān)聯(lián)
- Flink同時(shí)支持基于EventTime和ProcessingTime的流流join�。
- Interval join 已經(jīng)支持inner ,left outer, right outer , full outer 等類(lèi)型的join�,由此來(lái)看官網(wǎng)對interval join
類(lèi)型支持的說(shuō)明不夠準確�����。
- 當前版本Interval join的兩條流的消息清理是基于兩條流共有的combinedWatermark(較小的流的watermark)����。
- 流的watermark不會(huì )用于將消息直接過(guò)濾掉���,即時(shí)消息在本流中的watermark表示中已經(jīng)遲到���,但會(huì )直接將遲到的消息根據
相應的join類(lèi)型或輸出或丟棄�。
維表Join
維表(Dimension Table)是來(lái)自數倉建模的概念���。在數倉模型中�,事實(shí)表(Fact Table)是指存儲有事實(shí)記錄的表��,如系統
日志����、銷(xiāo)售記錄等�����,而維表是與事實(shí)表相對應的一種表����,它保存了事實(shí)表中指定屬性的相關(guān)詳細信息���,可以跟事實(shí)表做關(guān)
聯(lián)�����;相當于將事實(shí)表上經(jīng)常重復出現的屬性抽取�����、規范出來(lái)用一張表進(jìn)行管理�����。
在實(shí)際生產(chǎn)中����,我們經(jīng)常會(huì )有這樣的需求�,以原始數據流作為基礎���,關(guān)聯(lián)大量的外部表來(lái)補充一些屬性��。這種查詢(xún)操作就是
典型的維表 JOIN���。
使用維表的好處
- 縮小了事實(shí)表的大小�����。
- 便于維度的管理和維護����,增加��、刪除和修改維度的屬性�����,不必對事實(shí)表的大量記錄進(jìn)行改動(dòng)����。
- 維度表可以為多個(gè)事實(shí)表重用�����,以減少重復工作���。
維表JOIN使用
由于維表是一張不斷變化的表(靜態(tài)表視為動(dòng)態(tài)表的一種特例)����,因此在維表 JOIN 時(shí)���,需指明這條記錄關(guān)聯(lián)維表快照的對
應時(shí)刻����。Flink SQL 的維表 JOIN 語(yǔ)法引入了 Temporal Table 的標準語(yǔ)法����,用于聲明流數據關(guān)聯(lián)的是維表哪個(gè)時(shí)刻的快照����。
需要注意是��,目前原生 Flink SQL 的維表 JOIN 僅支持事實(shí)表對當前時(shí)刻維表快照的關(guān)聯(lián)(處理時(shí)間語(yǔ)義)�����,而不支持事實(shí)
表 rowtime 所對應的維表快照的關(guān)聯(lián)(事件時(shí)間語(yǔ)義)����。
語(yǔ)法說(shuō)明
Flink SQL 中使用語(yǔ)法 for SYSTEM_TIME as of PROC_TIME()來(lái)標識維表JOIN���。僅支持 INNER JOIN和 LEFT JOIN��。
SELECT
column-namesFROM
table1 [AS <alias1>][LEFT]
JOIN table2 FOR SYSTEM_TIME AS OF table1.proctime [AS <alias2>]
ON table1.column-name1 = table2.key-name1
注意:
table1.proctime表示 table1的 proctime字段�。
使用示例
下面用一個(gè)簡(jiǎn)單的示例來(lái)展示維表 JOIN 語(yǔ)法��。假設我們有一個(gè) Orders 訂單數據流��,希望根據用戶(hù) ID 補全訂單中的用戶(hù)
信息�,因此需要跟 Customer 維度表進(jìn)行關(guān)聯(lián)��。
CREATE TABLE Orders (
id INT,
price DOUBLE,
quantity INT,
proc_time AS PROCTIME(),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'datagen',
'fields.id.kind' = 'sequence',
'rows-per-second' = '10'
);
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
CREATE TABLE OrderDetails (
id INT,
total_price DOUBLE,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/orderdb',
'table-name' = 'orderdetails'
);
-- enrich each order with customer information
INSERT INTO OrderDetails
SELECT
o.id,
o.price,
o.quantity,
c.country,
c.zipFROM
Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.id = c.id;
Flink SQL 執行流程
Apache Calcite 是一款開(kāi)源的 SQL 解析工具�,被廣泛使用于各個(gè)大數據項目中��,主要用于解析 SQL 語(yǔ)句�。SQL 的執行流程
一般分為四個(gè)主要階段:
- Parse:語(yǔ)法解析�,把 SQL 語(yǔ)句轉換成抽象語(yǔ)法樹(shù)(AST)�,在 Calcite 中用 SqlNode 來(lái)表示���;
- Validate:語(yǔ)法校驗��,根據元數據信息進(jìn)行驗證����,例如查詢(xún)的表���、使用的函數是否存在等�,校驗之后仍然是 SqlNode 構
成的語(yǔ)法樹(shù)��;
- Optimize:查詢(xún)計劃優(yōu)化�����,包含兩個(gè)階段��,1)將 SqlNode 語(yǔ)法樹(shù)轉換成關(guān)系表達式 RelNode 構成的邏輯樹(shù)��,2)使用優(yōu)
化器基于規則進(jìn)行等價(jià)變換�,例如謂詞下推���、列裁剪等���,經(jīng)過(guò)優(yōu)化器優(yōu)化后得到最優(yōu)的查詢(xún)計劃����;
- Execute:將邏輯查詢(xún)計劃翻譯成物理執行計劃����,生成對應的可執行代碼��,提交運行���。